Recent discoveries in computational neuroscience hold important implications for how humans learn and make decisions

How does dopamine help us make important decisions? What kinds of learning scenarios best enable us to become proficient at something? And why does overthinking sometimes hinder learning? Professor Michael Frank’s lab has published scholarship that responds to these questions. The Director of Carney’s Center for Computational Brain Science, Frank’s research combines computational modeling and experimental work to understand the neural mechanisms underlying reinforcement learning, decision making and cognitive control.
Frank sat down with Carney’s communications team to discuss two new and interconnected journal articles coming out of research.
Carney Institute (CI): You study how dopamine operates in the brain using both computational models and experiments with humans and animals. Can you give us an overview?
Michael Frank (MF): For a long time people have been interested in answering the question, “What does dopamine do in the brain”? Dopamine is involved in all sorts of behaviors, most starkly, motor function. Patients with Parkinson's disease have problems with movement because the neurons that make dopamine are dying.
More broadly, we now know that one of dopamine’s key roles is to facilitate multiple aspects of reinforcement learning. Reinforcement learning is the process by which we learn which actions to take to maximize rewards and minimize regret.
When a human or an animal engaged in a learning task obtains an outcome that is better than expected, dopamine neurons increase their activity. When the outcome is worse than expected, dopamine neurons decrease activity. Let’s say you’re anticipating a certain action will result in you getting one dollar, and it turns out that instead you get two dollars. The sense of surprise you feel is dopamine underscoring the better-than-anticipated consequences of your action, which helps to ingrain in your memory how to do the action in order to get these results again. We call this a reward prediction error, and it’s very important because, as the example illustrates, the brain learns from errors in its ability to predict future rewards.
But how does dopamine change behavior? It turns out that increases and decreases in dopamine induce learning in opposite directions along separate neural pathways within the striatum, a part of the basal ganglia. When dopamine goes up, it activates one pathway, helping the person to learn to choose the positive action. When it goes down, it activates the other pathway, allowing the person to learn which actions to avoid. We call these two pathways an opponent system: it’s a push-pull kind of circuitry.
There is another aspect to dopamine I want to touch on, usually studied separately from learning, where dopamine directly affects decision making. By changing activity in the opponent pathways, dopamine can tip the scales in terms of a choice a human or animal is weighing, causing animals or humans to make riskier decisions with potentially higher gains. Let’s say you’re playing a slot machine and you’re getting some good results and are deciding whether to wager more. That higher-than-normal amount of dopamine is responsible for the moment where you say, “I’m gonna go for it.”
CI: How does computational research come into it?
MF: Much of our insight into patterns and functions of the brain’s dopamine activity comes from models of how learning occurs, especially computer science and artificial intelligence models. At the same time, looking at the brain’s neural details inspires new ways of thinking about computation. As computational researchers, we are constantly moving back and forth between the two.
CI: And the two recent publications represent these two aspects of your work?
MF: Yes. In the first paper, we built a new computational model of the biological reinforcement learning system, which is in the basal ganglia and is shared by rodents all the way up to humans. In the second paper, we studied how the reinforcement learning system interacts with working memory, which is in the prefrontal cortex, and is more evolutionarily advanced. We ran experiments with humans while recording their electrical brain activity to see how the results confirm or refute what we’ve modeled computationally.
CI: Let’s first discuss the paper you published in eLife, with Alana Jaskir, a cognitive science Ph.D. candidate, as the lead author.
MF: So, standard computer science models of learning don’t operate the same way the basal ganglia does. Standard computational models have only one pathway of learning, whereas the basal ganglia has these two opponent systems I described.
What we wanted to find out in the eLife paper is why the brain would have evolved that particular complex circuitry. Why do you need two pathways, when in computer science there only tends to be one?
We built a computational model that has the important features of biological reinforcement learning I described: opponency, dopamine-mediated learning, and how dopamine changes across environments. What we learned from the experiments we ran is that there's far greater adaptability to having those two pathways.
CI: Can you elaborate?
Let’s say you're at a restaurant and you are choosing between salmon and steak. Your reinforcement learning system allows you to learn your net preference based on the multitude of times you've ordered those things in the past.
Your gut-level intuition about what to choose comes in part from the opponent system in your brain, which enables you to vary strategies. Sometimes it makes sense to take a strategy in which you want to optimize the best possible benefit: "I'm in a fancy restaurant. I should try the most succulent thing." Sometimes it makes sense to take a strategy where you want to minimize the worst possible cost: if you're in a place where you’re worried that it's not sanitary and could make you sick, your strategy is to avoid taking the action that's most likely to sicken you.
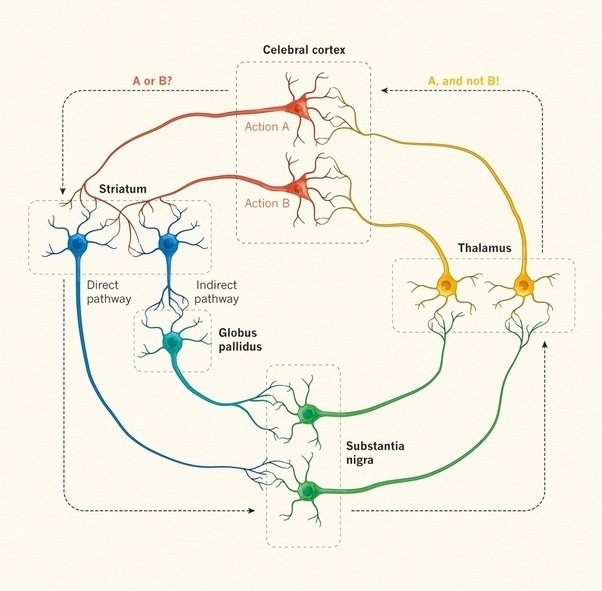
In our biologically-informed computational model of the basal ganglia, we found that having both pathways allows the system to learn to more finely discriminate between the benefits of alternative choices in one pathway, and the costs of alternative choices in another pathway. What’s more, we have found empirically that the advantage is yet more evident if we allow the dopamine system itself to adapt to the environment.
In a rich environment – an environment where there are a lot of rewards, like the fancy restaurant–dopamine rises. In a lean environment, like the situation where rewards are sparse and you’re worried about food poisoning, dopamine declines.
Then, when it’s time to make a decision, dopamine also directly recruits either the costs or benefits pathway depending on whether the environment is rich or lean.
Alana found that, especially in environments that are ecologically prevalent – when many actions are possible and rewards are sparse – this biologically-informed model optimizes performance more robustly than single system computational models. She showed that if she varies the tasks, any model that only has a single pathway may be able to solve some tasks, but will be really bad at others. Even when compared to a state-of-the-art algorithm that memorizes all the rewards it's ever seen for each choice, our biological model still performs better. It's one of the few examples we know of where taking into account how the animal brain does something in a more complex way actually shows computational advantage. To my knowledge, this is the first paper that provides a hypothesis for why the brain evolved this complex circuitry in the first place.
CI: What are some real-world implications for this discovery?
MF: Many patients are prescribed drugs that manipulate their dopamine systems. Both Parkinson’s patients and people with attention-deficit/hyperactivity disorder (ADHD) take drugs that increase dopamine levels. With schizophrenia, we block dopamine levels. Some people take drugs of abuse, which also increases dopamine levels.
Our model shows why drugs that manipulate dopamine are an imperfect solution. A drug that increases dopamine levels above normal is hijacking a person’s brain into thinking they’re in an environment where they should be taking the most reward-maximizing strategy, when actually, there may be costs. Such a drug is also ignoring one of the two pathways, when you really need both. You want dopamine levels to be low at the right time, where there are sparse rewards and many risks. While of course patients whose natural dopamine system is dysregulated can benefit from increased dopamine levels, there are cases when it is better to allow the brain to reduce its dopamine levels on its own because of its highly adaptive complex circuitry.
CI: Tell us what you discovered in the second paper, with Brown cognitive, linguistic and psychological sciences (CLPS) postdoc Rachel Rac-Lubashevsky as lead author, and in collaboration with Anna Cremer and Lars Schwabe, of the University of Hamburg.
MF: Working memory is what you're holding in mind: you're making decisions, you get some outcomes, and now you have to make that same decision again minutes or seconds later. It’s different from the basic reinforcement learning system, where the dopamine mechanism is slowly adjusting connections between neurons. Working memory allows us to hold in mind multiple things and thereby allows us to learn much more quickly, so we don't have to rely on and review our whole life history to figure out which actions are better than others. Working memory is in part what gives humans that adaptability that we have. It's much more flexible and fast than basic reinforcement learning.
But working memory is capacity-limited. You can only hold in mind a couple things before you start forgetting some. So, there's a trade-off between one system that is fast, adaptive and flexible, but is capacity-limited, and this more primitive reinforcement learning system that is slow but can robustly remember a huge number of previously learned strategies. This limited capacity is also related to why you can only effectively focus on one task at a time, unless the specific behaviors you are doing are routine.
Many of our lab’s experiments with people, including experiments conducted by my former postdoc and co-author, Anne Collins, support this dichotomy. They show when people only have to learn about one or two things at a time, they are faster to learn the best actions because they can just hold those in memory. But as we increase the number of actions they have to learn, people have more difficulty holding them in their minds and increasingly need to use the slower reinforcement learning system. So, unsurprisingly, we find that people learn more slowly as we introduce more actions.
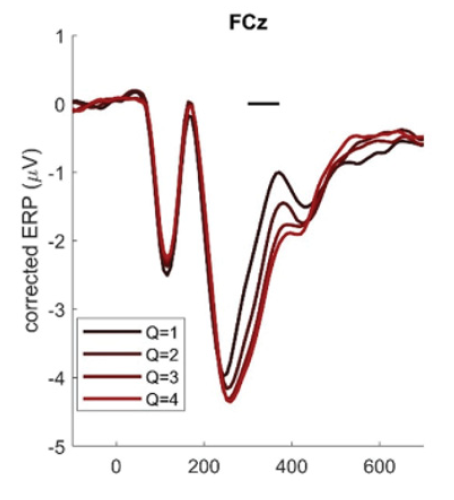
reinforcement learning and how it grows in
relation to an increasing working memory load.
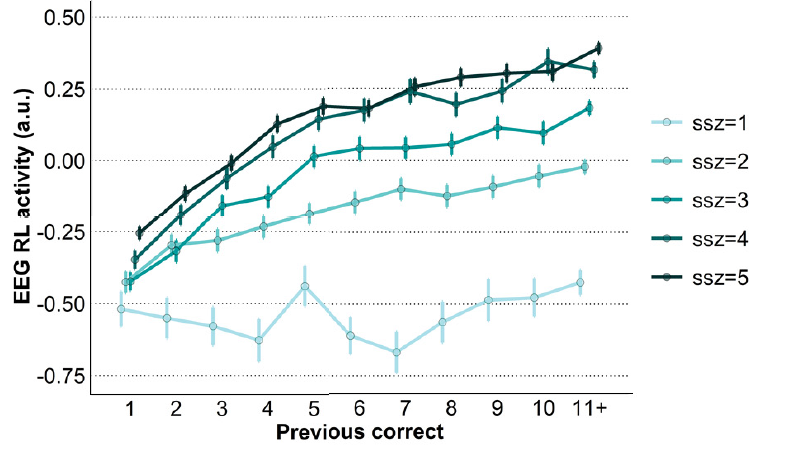
What is striking, and what we saw quite dramatically in this paper is that the opposite is true in terms of robustness of subjects’ learning. Rachel found the task that was the easiest to learn initially, subjects remembered the worst. If people solved the initial task with working memory, when they later needed to remember the best action, they no longer had it in mind, and pretty much forgot what to do. But when it came to the tasks that were initially hardest to learn, subjects remembered them almost perfectly.
Using computational models, my lab has predicted this result in previous publications. When your working memory is taxed, we have theorized, you are surprised you are correct. That sense of surprise is a burst of dopamine: a large reward prediction error that more strongly ingrains learning in your brain about which action to select.
Rachel tested this prediction by analyzing electrical brain activity while people were performing learning tasks. She found a neural signature of reinforcement learning in people’s brains. Finding this neural signature was critical, because if we just observed subjects’ behavior while doing tasks, it looked like they were learning better with the easiest tasks. But because we were able to observe the neural signature, we were able to see it went up more rapidly for the items that were hardest to learn. Then the degree to which that happened was predictive of how much they were able to remember when we checked in later.
To sum up, what we modeled computationally in the first paper, we were able to see strong evidence of via human electrical brain activity in the second paper.
CI: What areas would these insights apply to and how can they be put to use?
The work has implications for patient populations with alterations to their working memory and prefrontal systems, such as people with schizophrenia and people with certain learning disabilities. While it may appear from their behavior that they are struggling with a more challenging learning task, if the goal is to enhance long-term learning, this might be a strategy to consider.
For neurotypical populations, the implications are skills like music and sports. You might learn initially by thinking about it with working memory, but if you’re playing a guitar solo, you're not thinking about music theory. You're just knowing intuitively. And in fact, you could overthink it. That's why coaches and instructors give professional athletes or musicians strategies to not overthink.
Our research indicates that if you want something to become really swift and automatic, you should try practicing when you are slightly overloaded with distraction. Then, if you can produce good outcomes, your brain will be more surprised. It will experience that reward prediction error. So even if you may take a hit initially in your performance, if you do that enough, you'll become an expert.



